When many people start learning data engineering, tutorials usually feel manageable.
You read a CSV file.
Transform some data.
Run a Spark job.
Write output somewhere.
Everything feels clean and isolated.
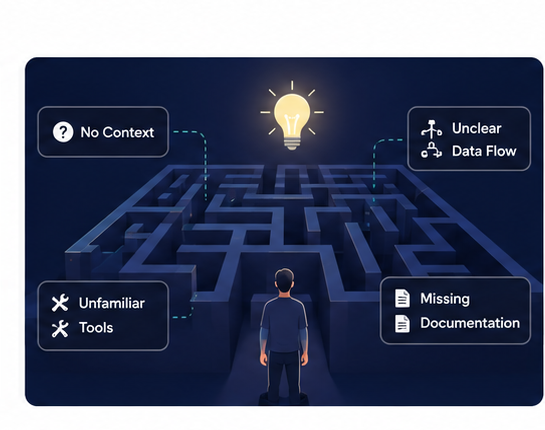
But the moment engineers enter a real company environment, things suddenly start feeling much more confusing.
There are multiple systems.
Different teams.
Pipelines depending on other pipelines.
Monitoring.
Retries.
Backfills.
Unexpected failures.
Temporary fixes.
Audit tables.
Schedules.
Permissions.
Suddenly it feels like there are too many moving parts.
This is one of the biggest reasons many engineers feel intimidated initially.
The problem is usually not intelligence.
The problem is exposure.
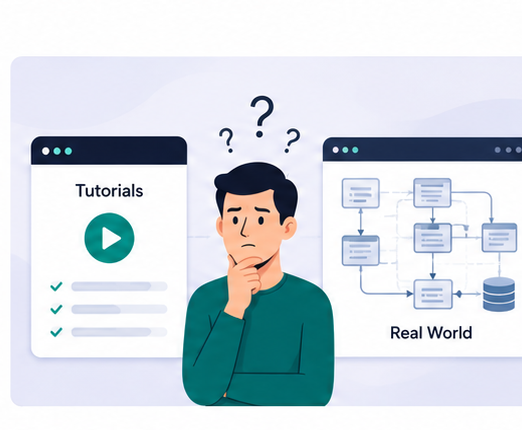
Most tutorials teach isolated tools.
Real engineering work involves understanding connected systems.
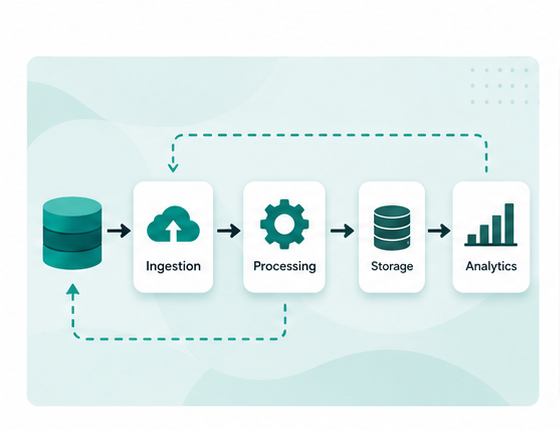
For example, a simple “daily pipeline” in production may involve:
- ingestion jobs
- orchestration
- retries
- monitoring
- warehouse tables
- reporting systems
- downstream dependencies
- operational handling when things fail
This is why many engineers feel a gap between tutorials and real systems.
The goal should not be to memorize every tool.
The goal is slowly becoming comfortable exploring unfamiliar systems.
That confidence develops through repeated exposure to real workflows, not just isolated demos.
Over time, systems that initially feel intimidating start becoming much easier to reason about.
That transition is an important part of becoming a stronger engineer.