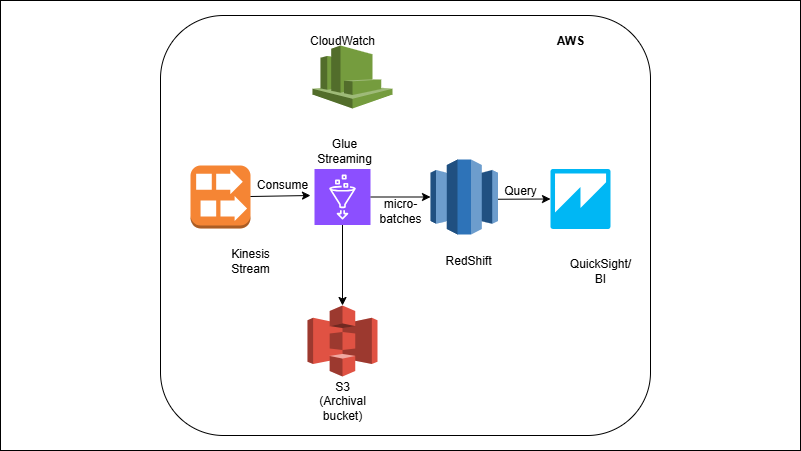
Build real-world data engineering systems using AWS-native and open-source technologies.
Deploy production-style pipelines covering ingestion, CDC, lakehouse architecture, orchestration, analytics, CI/CD, and exports — directly inside your own AWS account.