Data Engineering Pipelines
Hands-on, production-style data engineering pipelines you can run, reuse, and learn from – built the same way data teams design them in real projects.
On-Prem Pipelines
Learn core data engineering foundations — Sqoop, Hive, and PySpark — in an on-prem setup that mirrors enterprise batch ETL.
-
RDBMS → Sqoop → HDFS/Hive (Batch Ingestion)
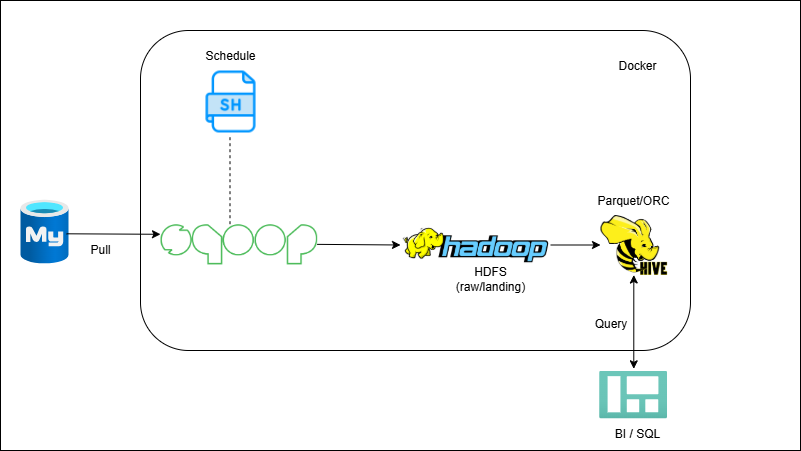
-
Files on HDFS → PySpark ETL → Parquet/ORC → Hive (Batch ETL)
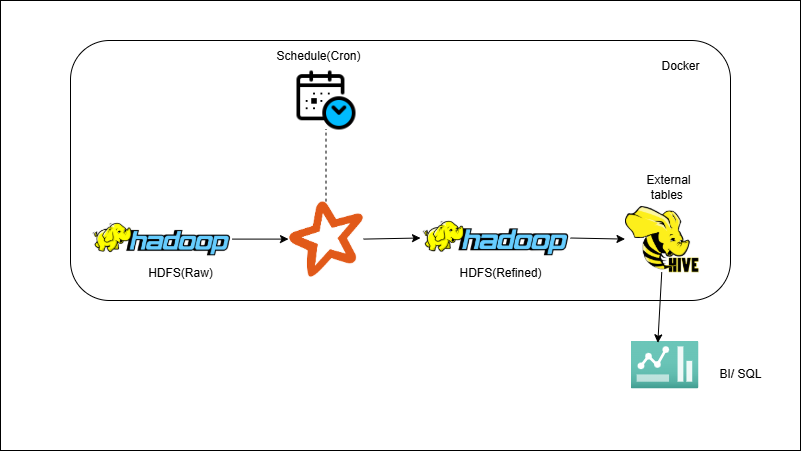
-
HDFS → PySpark → MySQL (Write-Back)
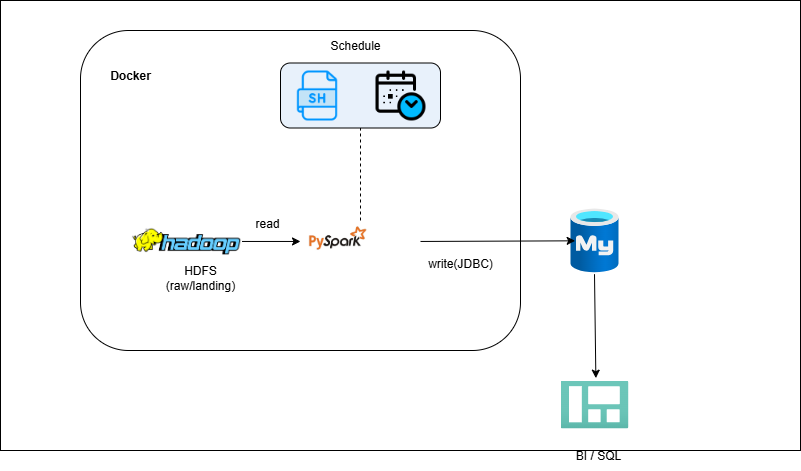
-
HDFS → Shell → SFTP Partner Delivery (Reverse ETL)
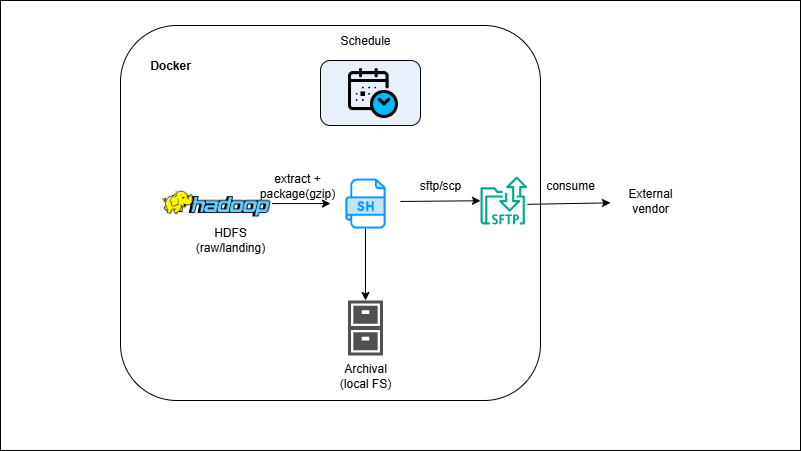
GCP Pipelines
Explore modern cloud workflows with BigQuery, Dataflow, and Composer. Each project reflects how GCP teams automate ingestion and transformations.
-
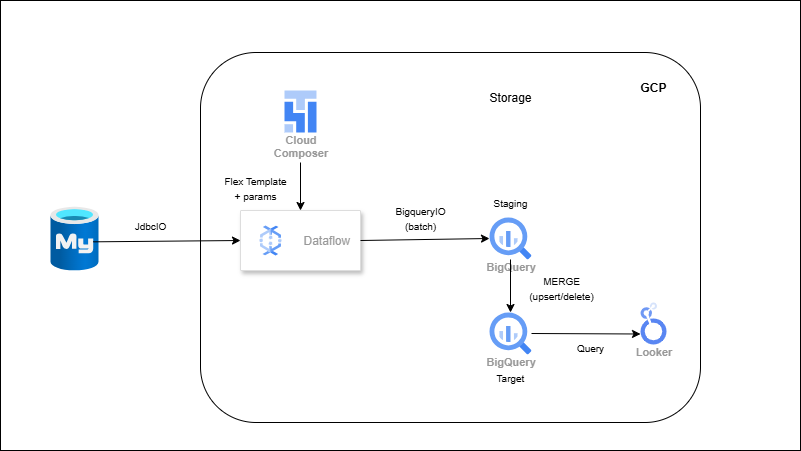
RDBMS → Dataflow (Flex Template) → BigQuery (Batch Ingestion)
-
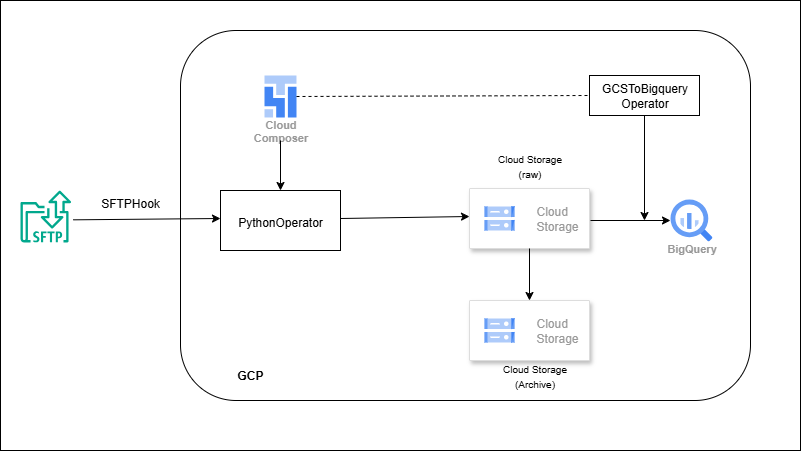
SFTP → Composer (Airflow) → GCS → BigQuery
-
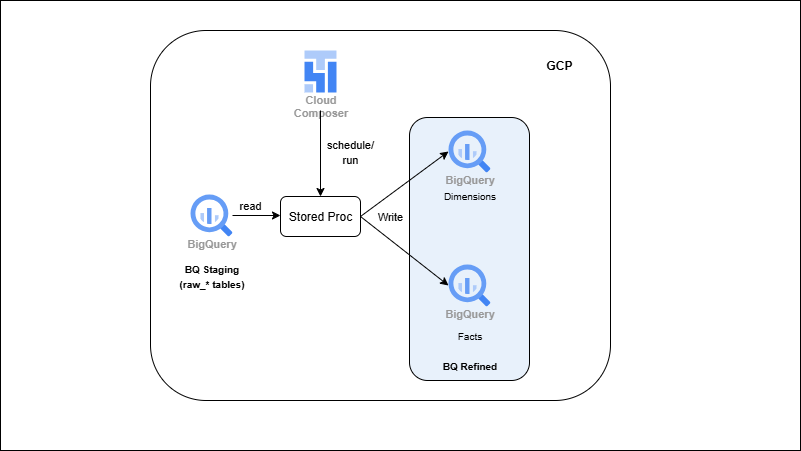
BigQuery Stored Procedures → ELT & SCD
-
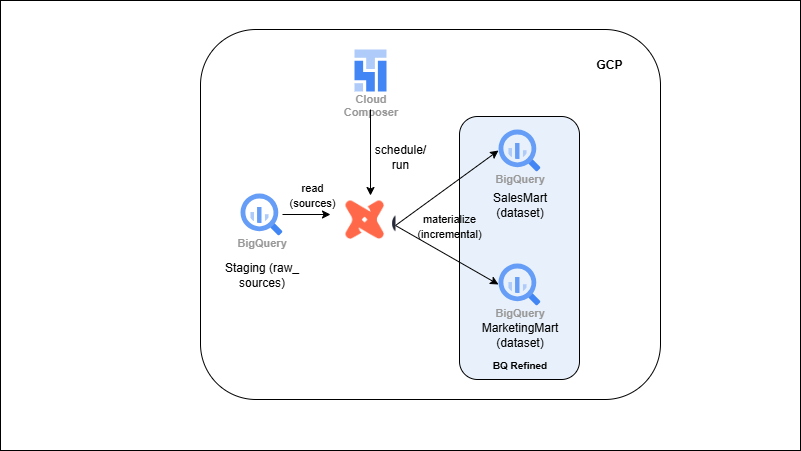
BigQuery + dbt (Modular ELT)
-
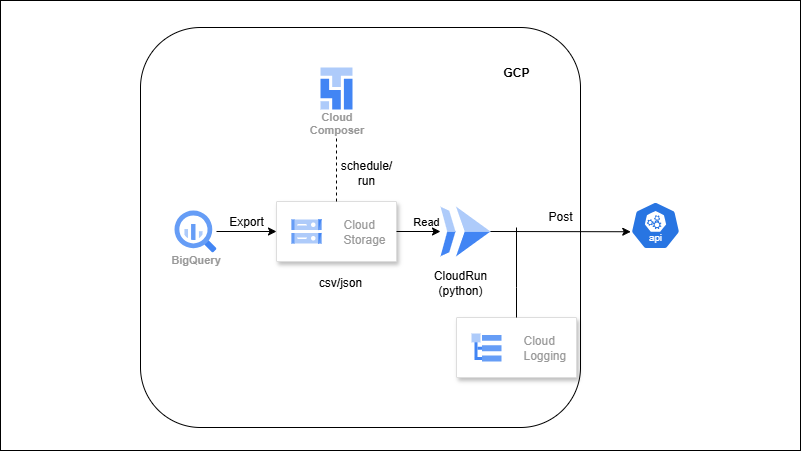
BigQuery → CSV Export → Vendor Delivery (Reverse ETL)
-
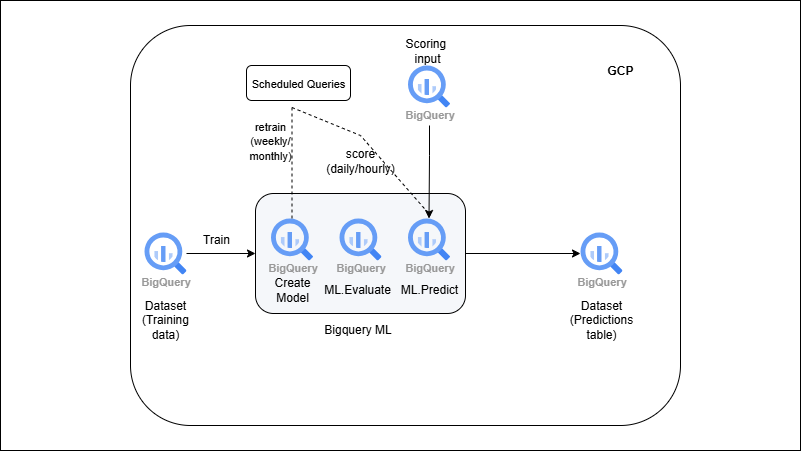
BigQuery ML → Train & Predict
-
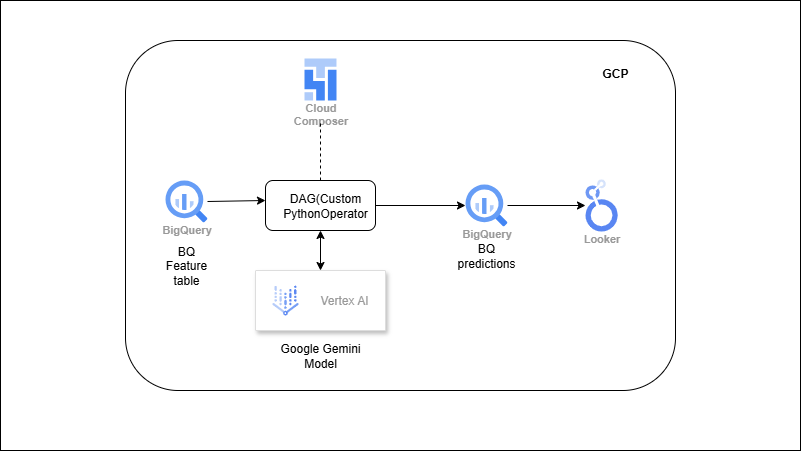
Vertex AI → Predict → BigQuery (ML Pipeline)
AWS Pipelines
Build and schedule data pipelines using S3, Glue, and Redshift, following best practices for scaling and orchestration.
-
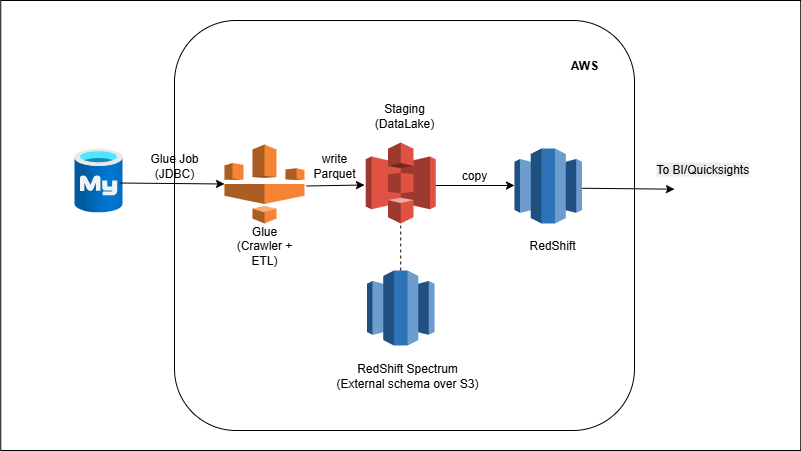
External RDBMS → Glue → S3 → Redshift (Batch Ingestion + ELT)
-
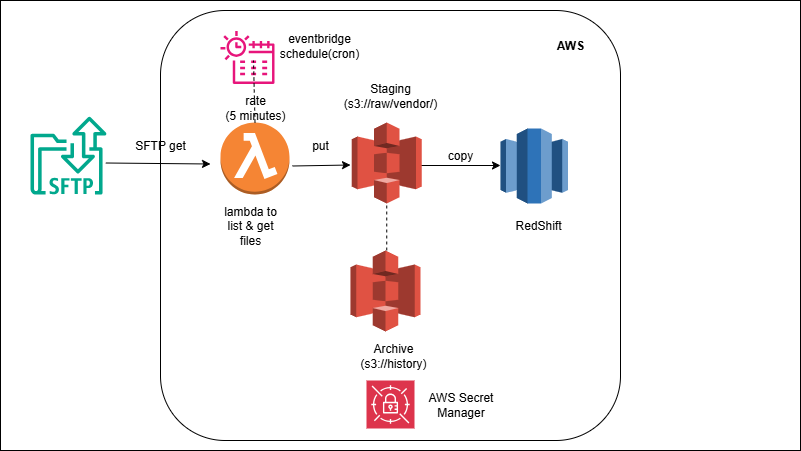
External SFTP → Lambda → S3 → Redshift COPY
-
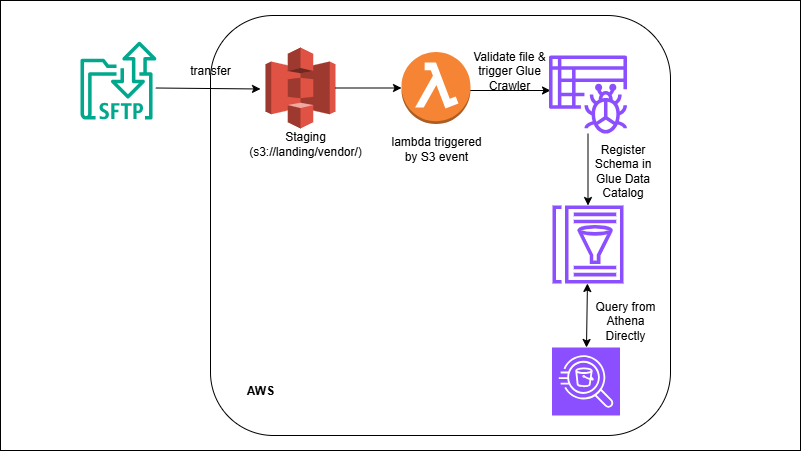
S3 Landing → Lambda → Athena (Serverless Analytics)
-
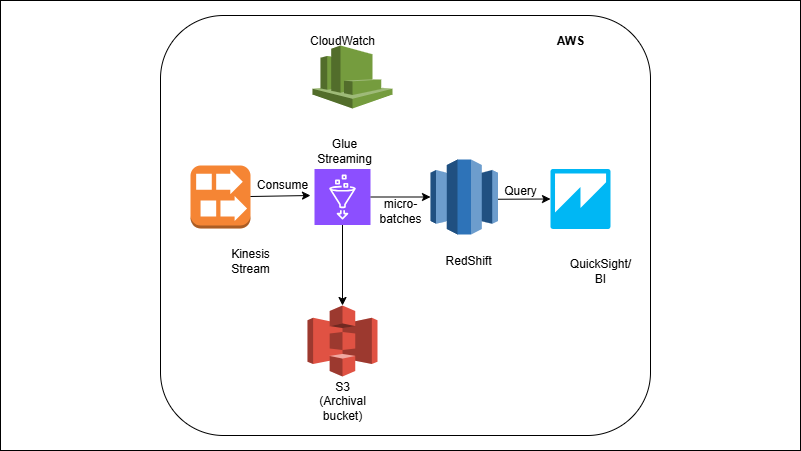
Kinesis → Glue Streaming → Redshift
-
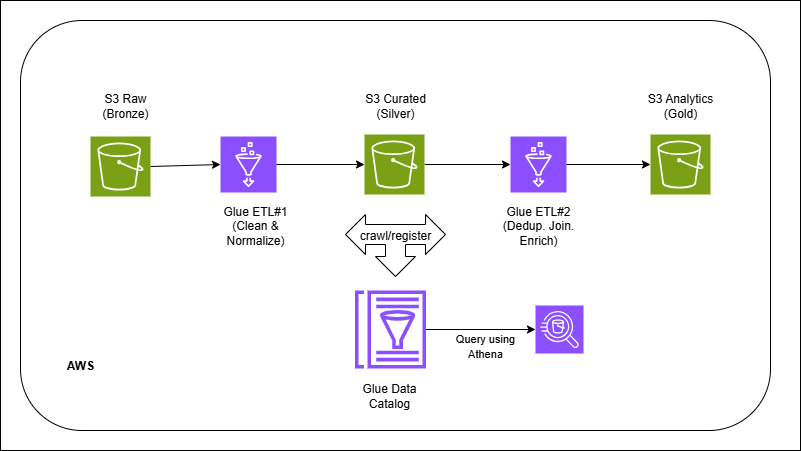
Glue → Data Lakehouse on S3 (Parquet)
-
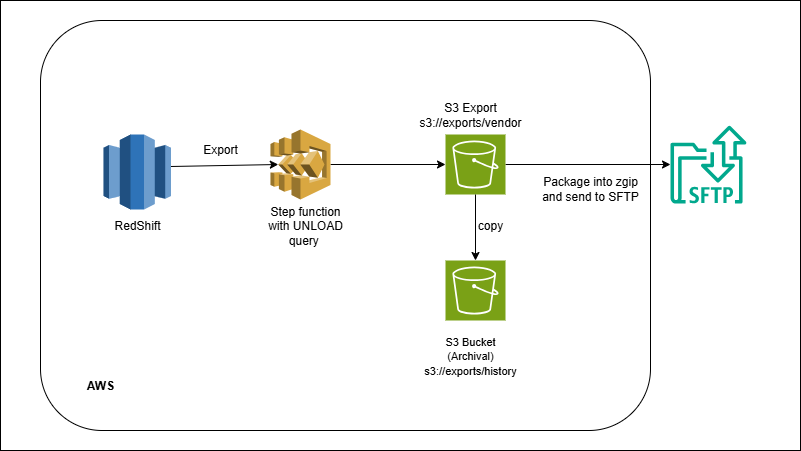
Redshift → UNLOAD → S3 → Partner SFTP (Reverse ETL)
Azure Pipelines
Work with Synapse, ADF, and Databricks in real-world style setups.
-
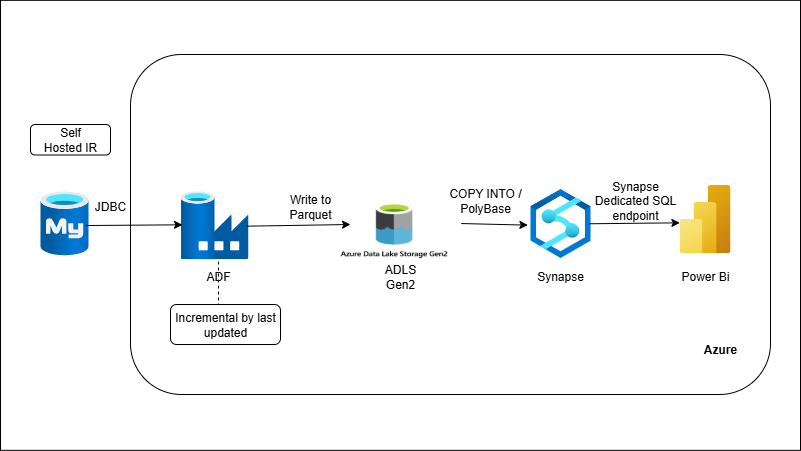
On-Prem RDBMS → ADF → ADLS → Synapse (Batch Ingestion + ELT)
-
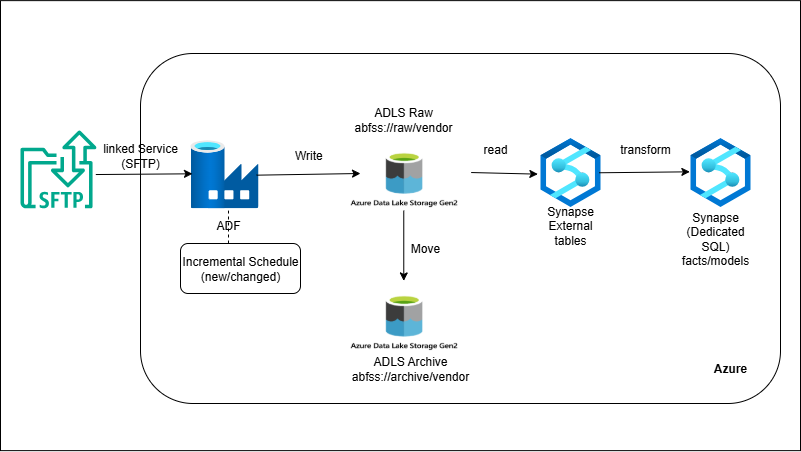
External SFTP → ADF → ADLS → Synapse
-
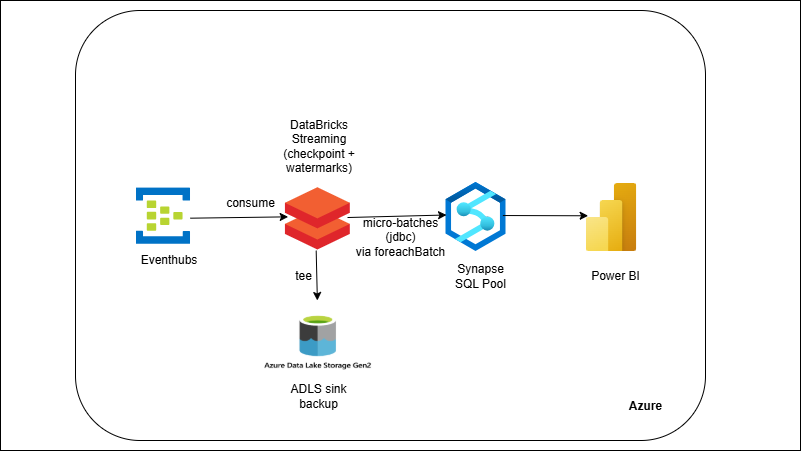
Event Hubs → Databricks Streaming → Synapse
-
ADF + Databricks → Medallion Architecture (Bronze/Silver/Gold)
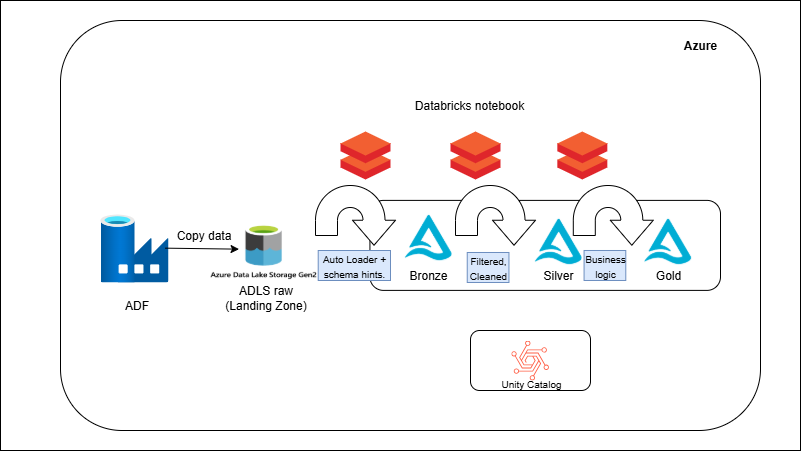
-
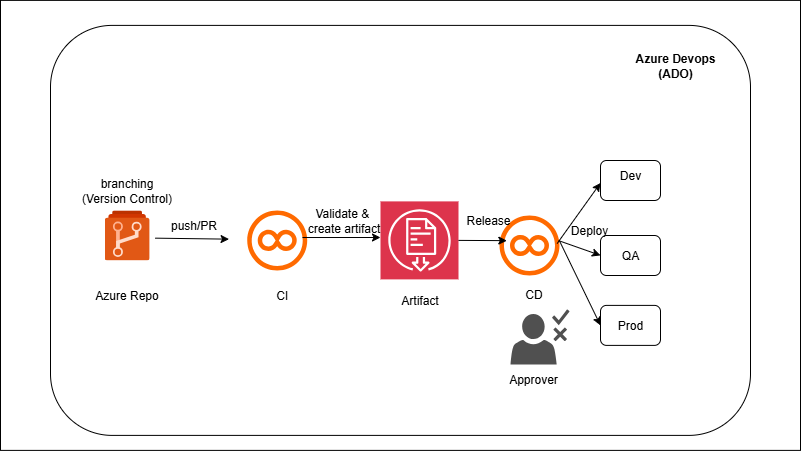
Azure DevOps CI/CD for Data Pipelines
❤️ Join the data0to1 community
Every learner gets private access to our WhatsApp / Discord group to ask questions, share progress, and stay on track.
Early access also includes occasional live support calls and early updates on new pipelines.