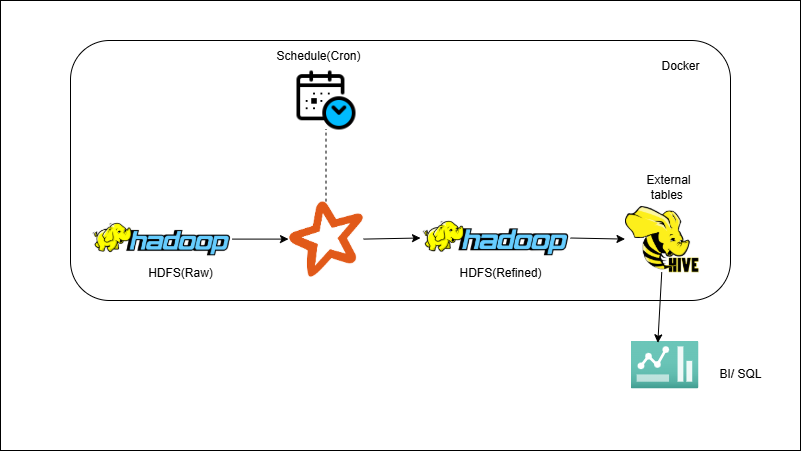
You’ll read raw CSV/JSON from HDFS into Spark DataFrames, apply core ETL logic (schema checks, dedupe, enrich with lookups), and write optimized Parquet/ORC datasets partitioned for performance. Then you’ll register external Hive tables on top of the refined paths for analytics. The job is scheduled via cron or Airflow to keep the refined layer fresh.