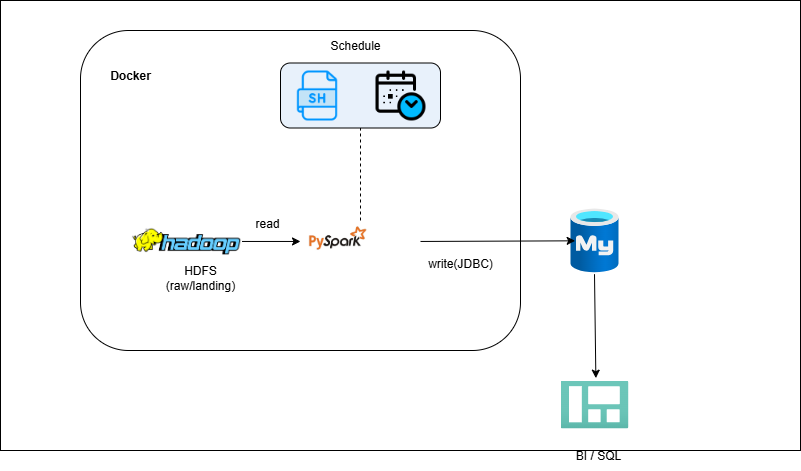
You’ll read raw/refined data from HDFS into Spark, compute daily aggregates (sales totals, active users, top products), and write them to MySQL using Spark’s JDBC sink. Loads are made idempotent by either overwriting targets or using key-based upserts. The job is scheduled with cron or orchestrated via Airflow so downstream apps and reports see fresh, consistent tables.