Included in Data0to1 Project Library
Silver data is clean and trusted, but analytics teams usually need data shaped into business-friendly tables.
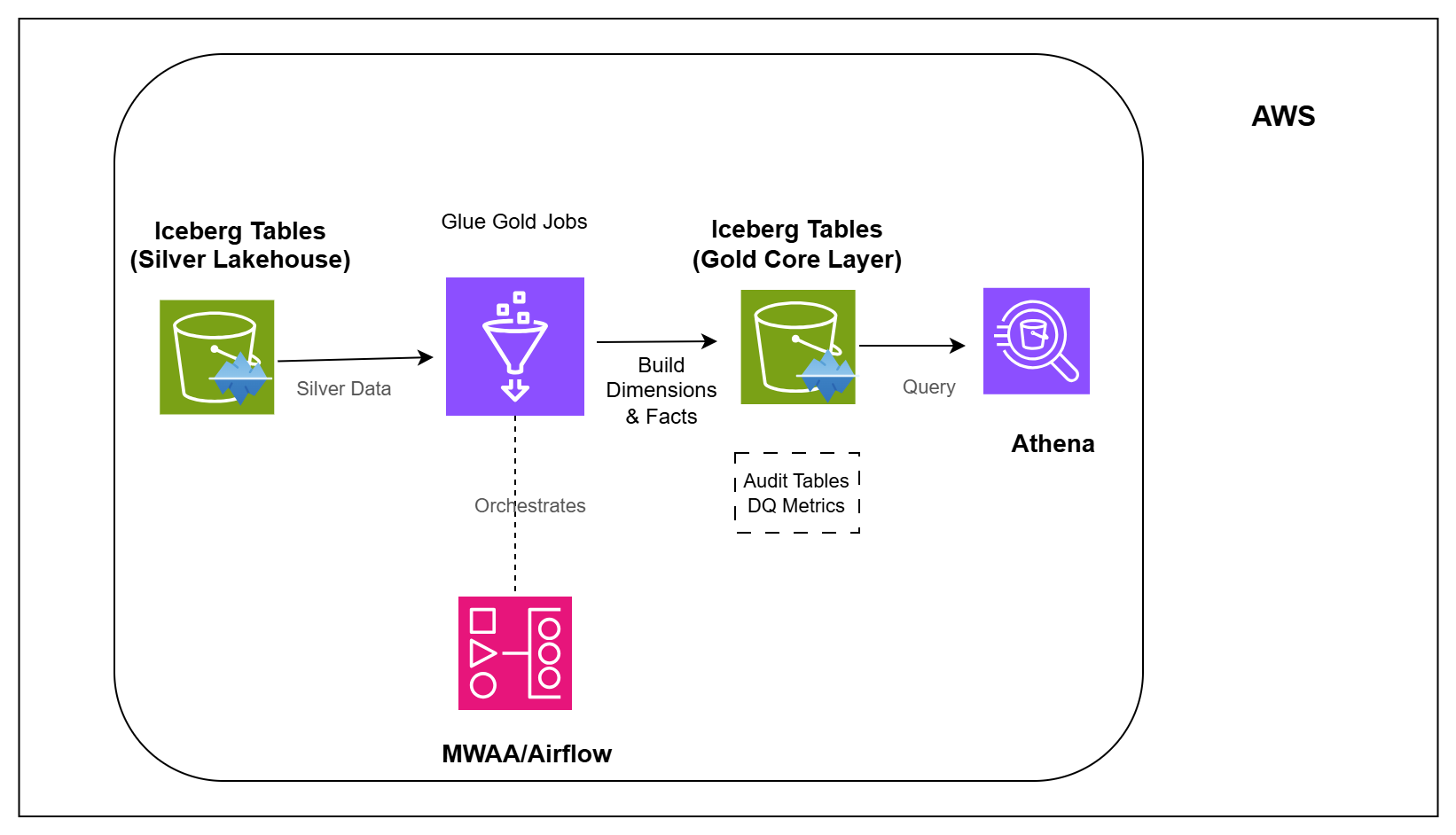
For reporting and downstream analytics, healthcare data often needs to be organized into dimensions such as patients, providers, departments, facilities, and dates, along with fact tables for encounters, vitals, labs, medications, diagnoses, procedures, charges, allergies, problems, and discharge summaries.
In this pipeline, you will create the Gold Core layer of an AWS lakehouse. You will transform Silver healthcare tables into business-ready dimension and fact tables, store them as Apache Iceberg tables on Amazon S3, track pipeline runs and quality checks, and validate the results using Athena.
After completing this pipeline, you will be able to:
Get access to the project code, setup files, architecture walkthrough, implementation videos, and support.