Included in Data0to1 Project Library
Payment applications store day-to-day data such as customers, merchants, KYC records, wallets, ledger entries, settlements, refunds, disputes, and device activity inside operational databases.
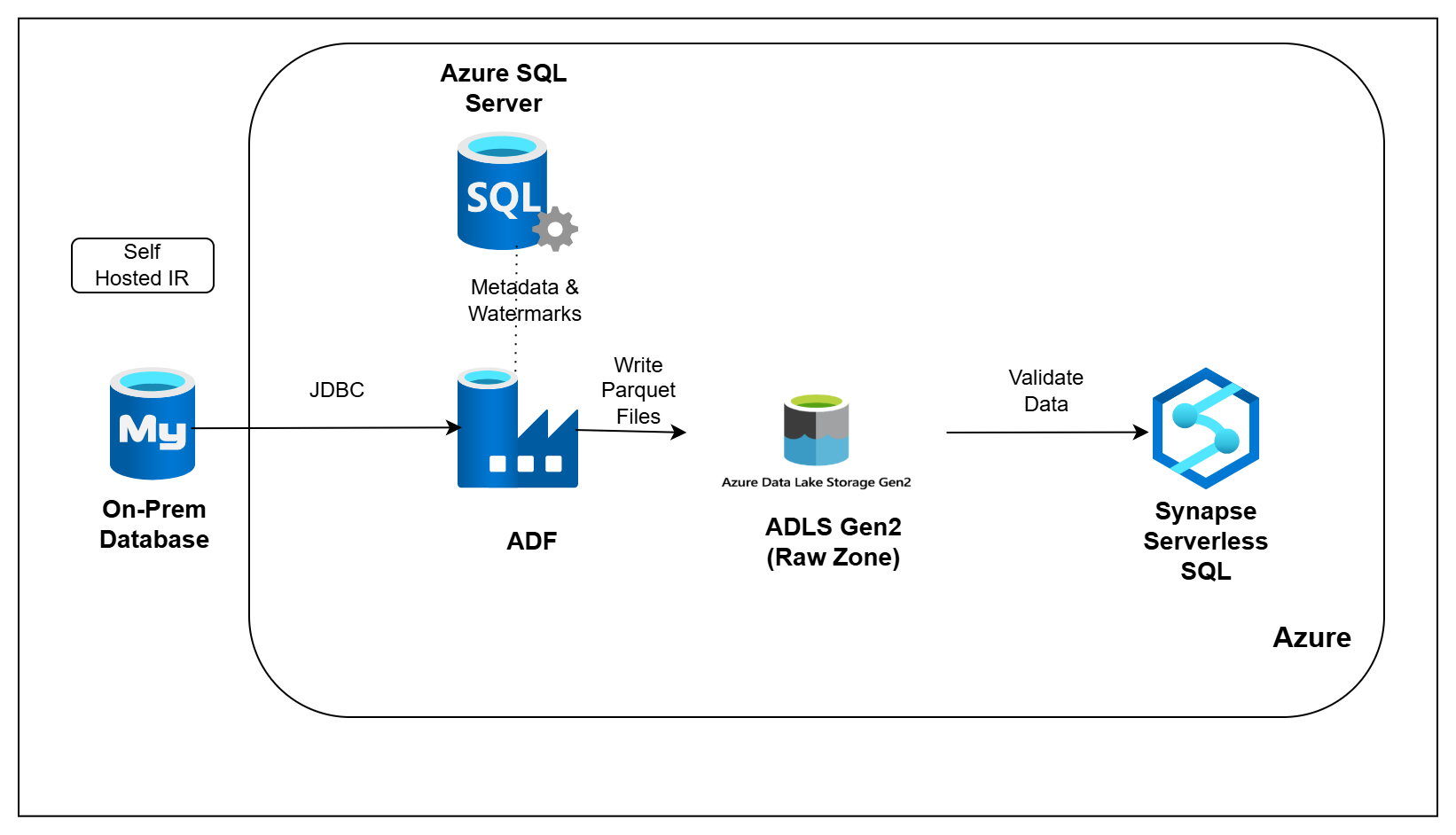
But analytics teams should not directly depend on the application database for reporting. In real projects, data is usually moved into a data lake first, where other teams and pipelines can safely use it.
In this pipeline, you will move payments data from MySQL into Azure Data Lake Storage Gen2 using Azure Data Factory. You will track each run using metadata tables, use watermarks to load only new or changed records, and validate ingestion results using Synapse Serverless SQL.
After completing this pipeline, you will be able to:
Get access to the project code, setup files, architecture walkthrough, implementation videos, and support.