Included in Data0to1 Project Library
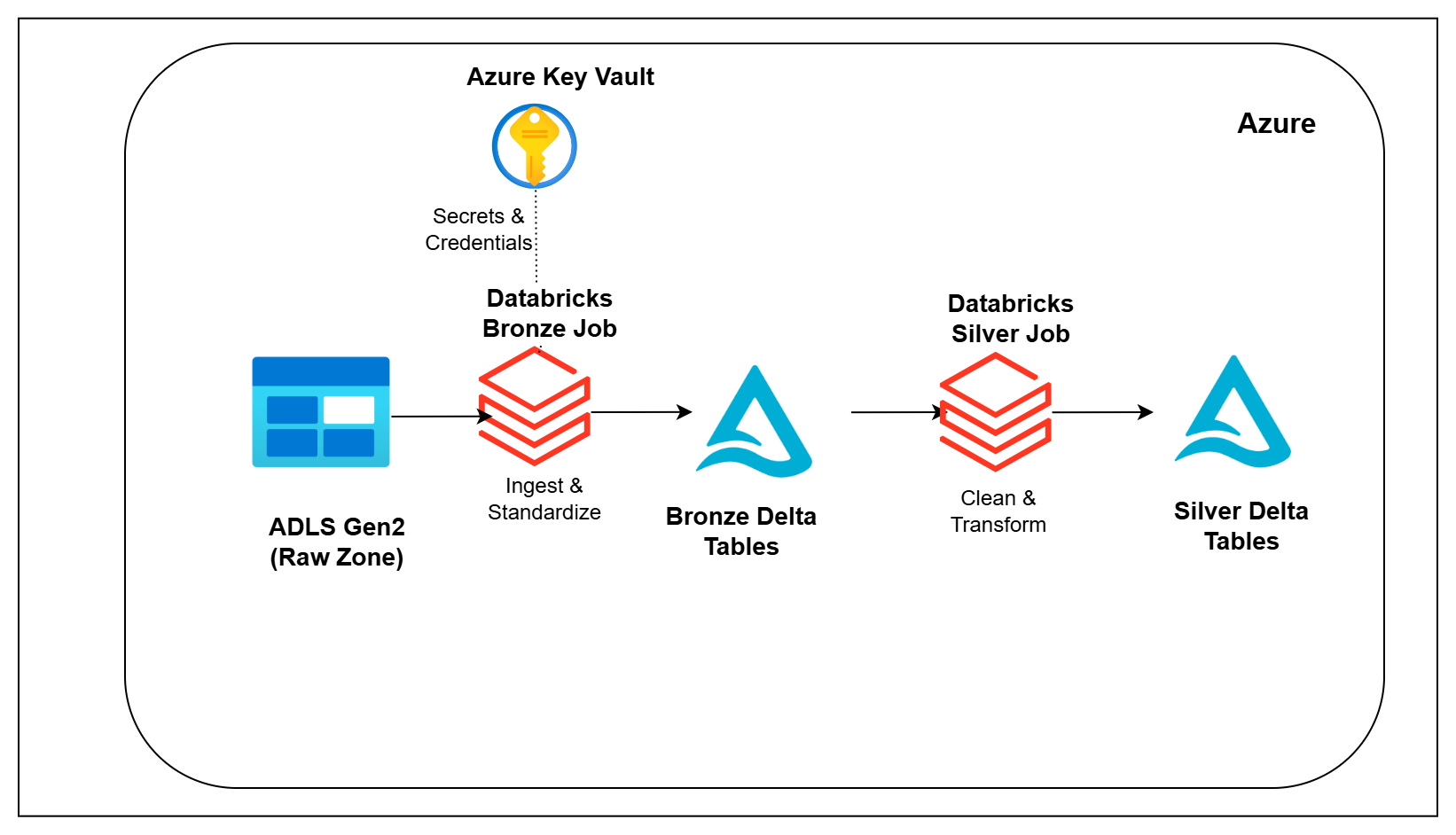
Raw data in a data lake is rarely ready for analytics.
Files may come from multiple systems, contain duplicates, use different formats, or require standardization before downstream teams can trust them.
In this pipeline, you will create the Bronze and Silver layers of an Azure lakehouse. You will read raw payments data from ADLS Gen2, use Azure Databricks and Delta Lake to create Bronze tables with lineage and audit information, transform the data into trusted Silver tables, remove duplicates using latest-record logic, and validate the results using Synapse Serverless SQL.
After completing this pipeline, you will be able to:
Get access to the project code, setup files, architecture walkthrough, implementation videos, and support.