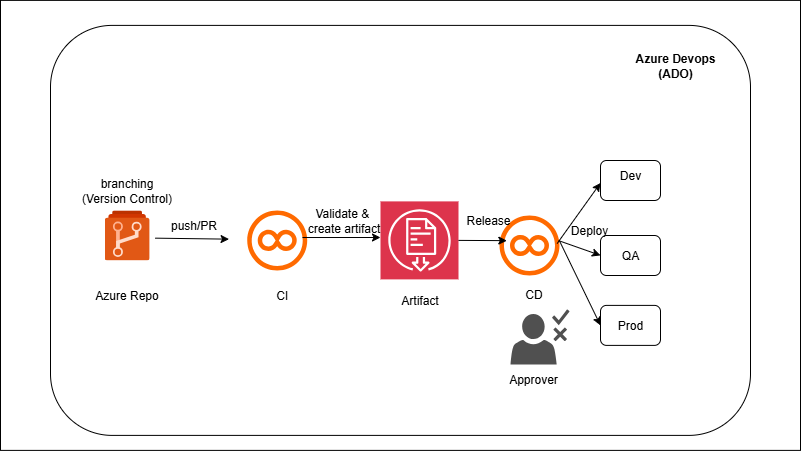
You’ll connect ADF to Git (collaboration branch) so each publish generates ARM templates in `adf_publish`. A build pipeline packages those templates and the Databricks assets (notebooks, job configs). A multi-stage YAML then deploys: Stage Dev runs ARM/Bicep to update ADF and uses the Databricks CLI/dbx to import notebooks and create/update Jobs; the same artifact promotes to QA and Prod with environment-scoped variables and approvals. Secrets (connection strings, tokens) are referenced from Azure Key Vault so no secrets live in the repo.