Event Hubs → Databricks Streaming → Synapse
Overview
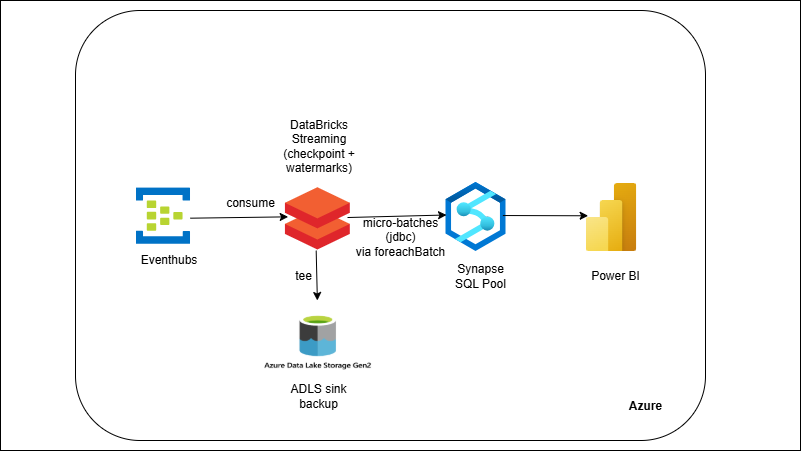
Events land in Event Hubs and are consumed by a Databricks Structured Streaming job. The job parses JSON, enforces schema, assigns event-time timestamps, and uses watermarks to handle late/duplicate events. Each micro-batch lands in Synapse (staging) and then merges into modeled tables for low-latency analytics. Checkpointing ensures fault tolerance; invalid messages are written to ADLS as a DLQ. Power BI can read Synapse for live dashboards.
Outcome
- Real-time ingestion from Event Hubs into Synapse analytics tables.
- Trustworthy streams with schema enforcement, watermarks, and dedupe.
- Resilient ops via checkpoints and idempotent upserts.
What you’ll build
- Event Hubs namespace + event hub (topic) and a simple producer (Python).
- Databricks notebook (Spark Structured Streaming) that:
-
- Reads Event Hubs, parses JSON → columns, applies watermarks.
- Computes real-time metrics (active sessions, order totals, etc.).
- Writes micro-batches to Synapse staging (JDBC/SQL DW connector).
- Runs MERGE/UPSERT into target fact/dim tables.
- Sends bad records to ADLS (DLQ) with error context.
- Checkpointing for exactly-once semantics across restarts.
- (Optional) Power BI dashboard over Synapse tables.