External RDBMS → Glue → S3 → Redshift (Batch Ingestion + ELT)
Overview
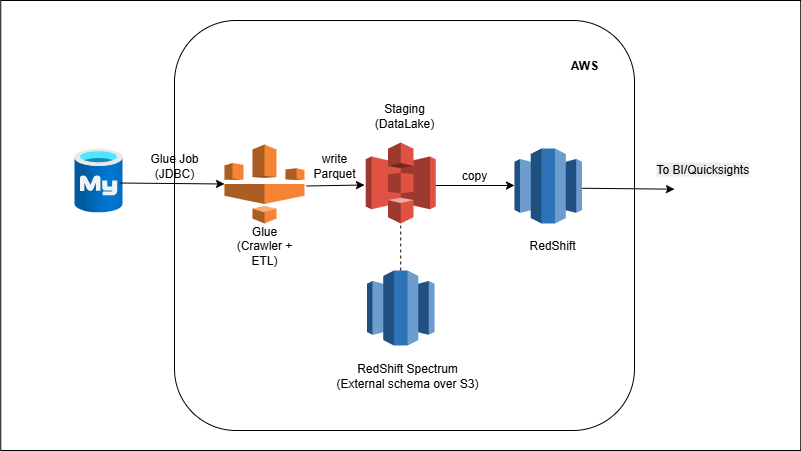
Glue connects to the external RDBMS (secured via JDBC + SSL and Secrets Manager), crawls schemas, and runs an ETL job that extracts tables to S3, converting to partitioned Parquet. Redshift loads from S3 via `COPY` into staging, then merges into modeled fact/dim tables with appropriate distribution and sort keys. A daily workflow (Glue Triggers/Step Functions) drives extract → transform → load, supporting incremental upserts and simple row-count checks.
Outcome
- Real-world external DB → AWS ingestion with secure JDBC/SSL.
- Cheaper/faster queries via Parquet + tuned dist/sort keys in Redshift.
- Repeatable daily upserts orchestrated by Glue Triggers/Step Functions.
What you’ll build
- Glue Connection to external DB (JDBC, SSL certs, Secrets Manager).
- Glue Crawler to register external schemas in the Data Catalog.
- Glue ETL job: extract → S3 (staging) → transform to Parquet (partitioned).
- Redshift COPY from S3 into staging, then MERGE/UPSERT to facts/dims.
- Incremental load pattern (watermark/updated_at) + simple validations.
- (Optional) Workflow with Glue Triggers / Step Functions; basic monitoring.