Glue → Data Lakehouse on S3 (Parquet)
Overview
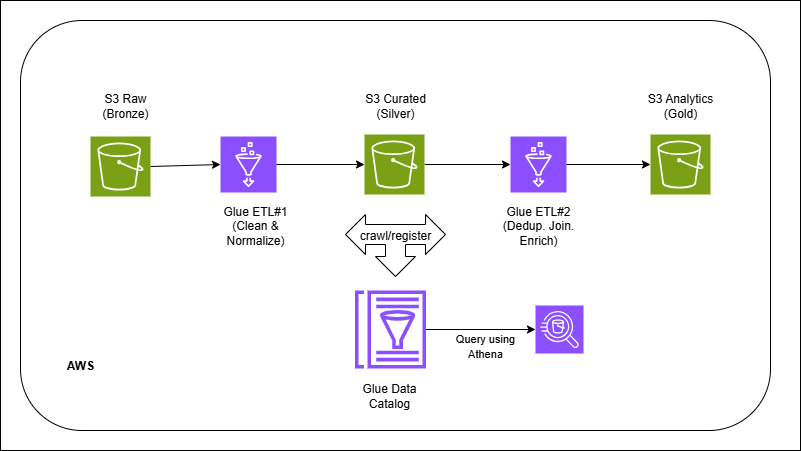
Files land in bronze exactly as received. Glue jobs standardize schema, clean/transform, and write columnar Parquet into silver with a consistent partitioned path. A second job aggregates/denormalizes into gold for analytics. The Glue Catalog registers tables so Athena/Spectrum can query instantly. Triggers/Workflows schedule bronze→silver→gold; a periodic compaction step merges small files to improve scan efficiency.
Outcome
- Lakehouse-style layers (raw → curated → analytics) on plain S3.
- Faster/cheaper queries via Parquet + partitioning and table metadata.
- Repeatable ETL with Glue triggers/workflows.
What you’ll build
- S3 layout: bronze/ (raw) → silver/ (cleaned) → gold/ (BI-ready).
- Glue ETL jobs (PySpark) to read JSON/CSV → standardize → write Parquet.
- Partitioning strategy (e.g., `dt=YYYY-MM-DD`, `product=`) and small-file compaction.
- Glue Data Catalog databases/tables for each zone.
- Query paths via Athena or Redshift Spectrum.
- (Optional) lightweight DQ checks (row counts, nulls) and a manifest.