Kinesis → Glue Streaming → Redshift
Overview
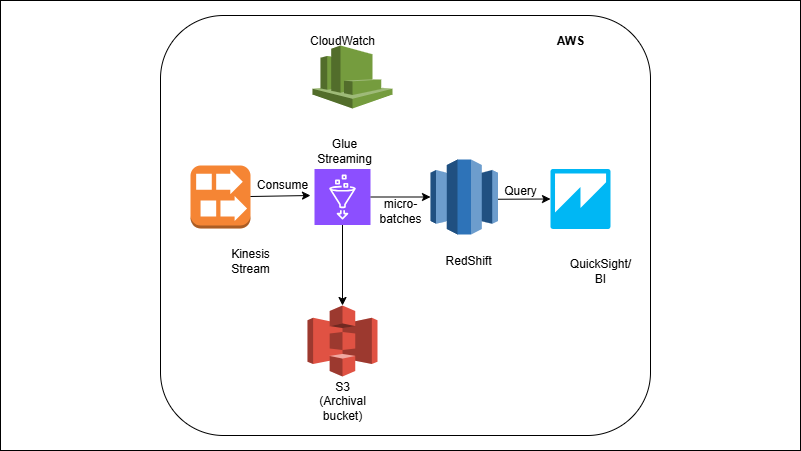
Events flow into Kinesis and are read by a Glue Streaming job using Spark Structured Streaming. The job parses JSON, applies light transforms, and lands rows to a Redshift staging table in micro-batches (e.g., every 1–5 minutes). A post-write step runs a MERGE to upsert into analytics tables, keeping them current without duplicates. Invalid records are parked in S3 (DLQ); CloudWatch and Glue provide throughput/latency/error metrics.
Outcome
- Near real-time ingestion from Kinesis into Redshift.
- Trustworthy tables via schema normalization and upsert/merge patterns.
- Operational visibility with Glue job metrics and Kinesis throughput.
What you’ll build
A Kinesis Data Stream + simple event producer (Python).
Glue Streaming job (Spark Structured Streaming) that:
- Consumes JSON, parses/validates schema, enriches with lookups.
- Writes micro-batches into Redshift staging (JDBC/Redshift Data API).
- Invokes MERGE/UPSERT into target facts/dims.
- Sends bad records to a DLQ (S3) with error context.
- Basic monitoring/alerts (CloudWatch metrics, failure notifications).
- (Optional) Orchestration via Step Functions.