Healthcare applications store important day-to-day data such as patients, providers, encounters, diagnoses, medications, vitals, allergies, and discharge information inside databases.
But this data cannot always be used directly for reporting or analytics from the same application database. In real projects, data is usually moved from the source system into a data lake first, so other teams and pipelines can safely use it.
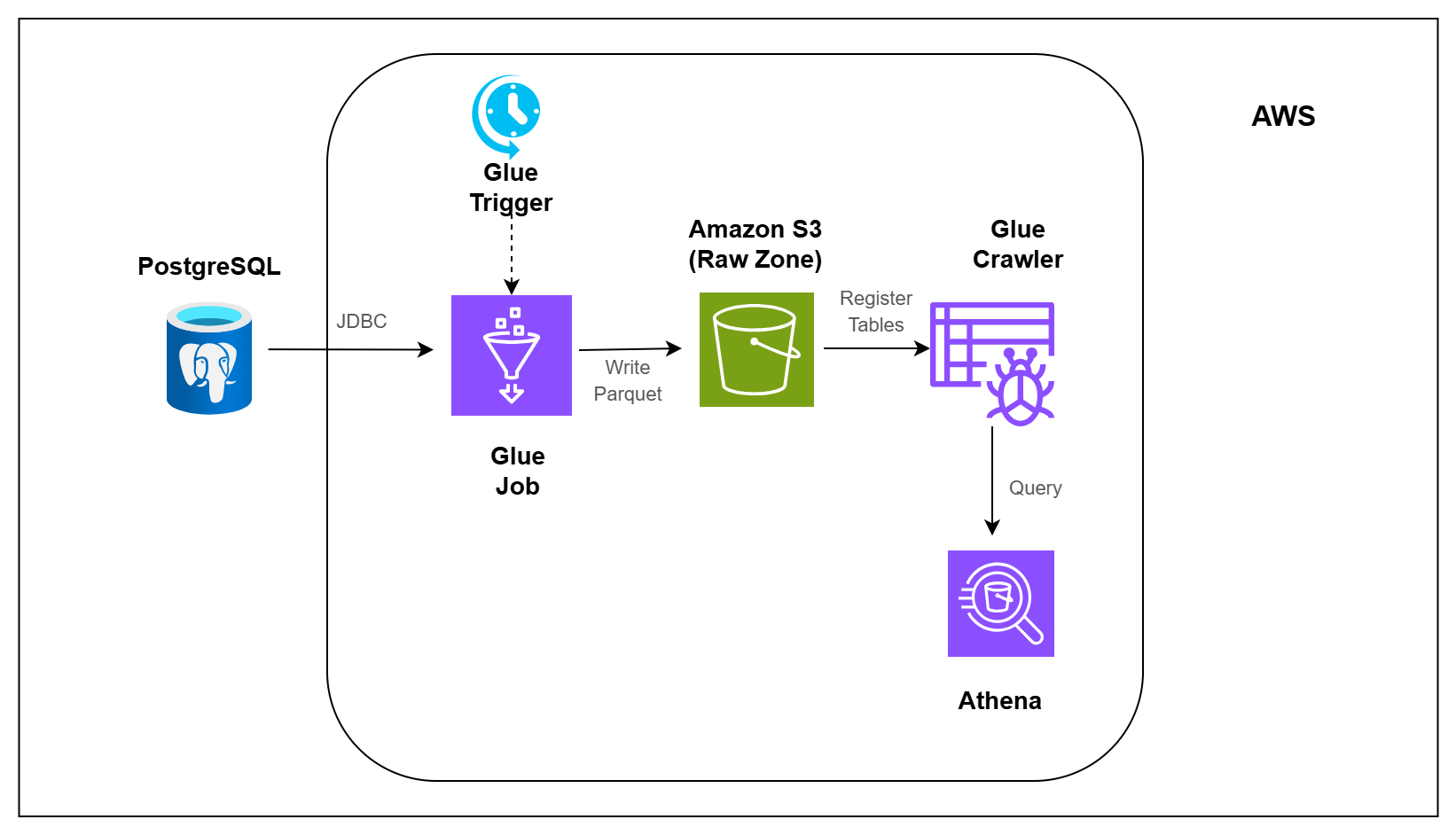
In this pipeline, you will build that first step.
You will take healthcare data from PostgreSQL, load it into Amazon S3, make the loaded data queryable, and schedule the pipeline so it can run repeatedly. Instead of loading the full database every time, the pipeline focuses on loading only new or changed records.