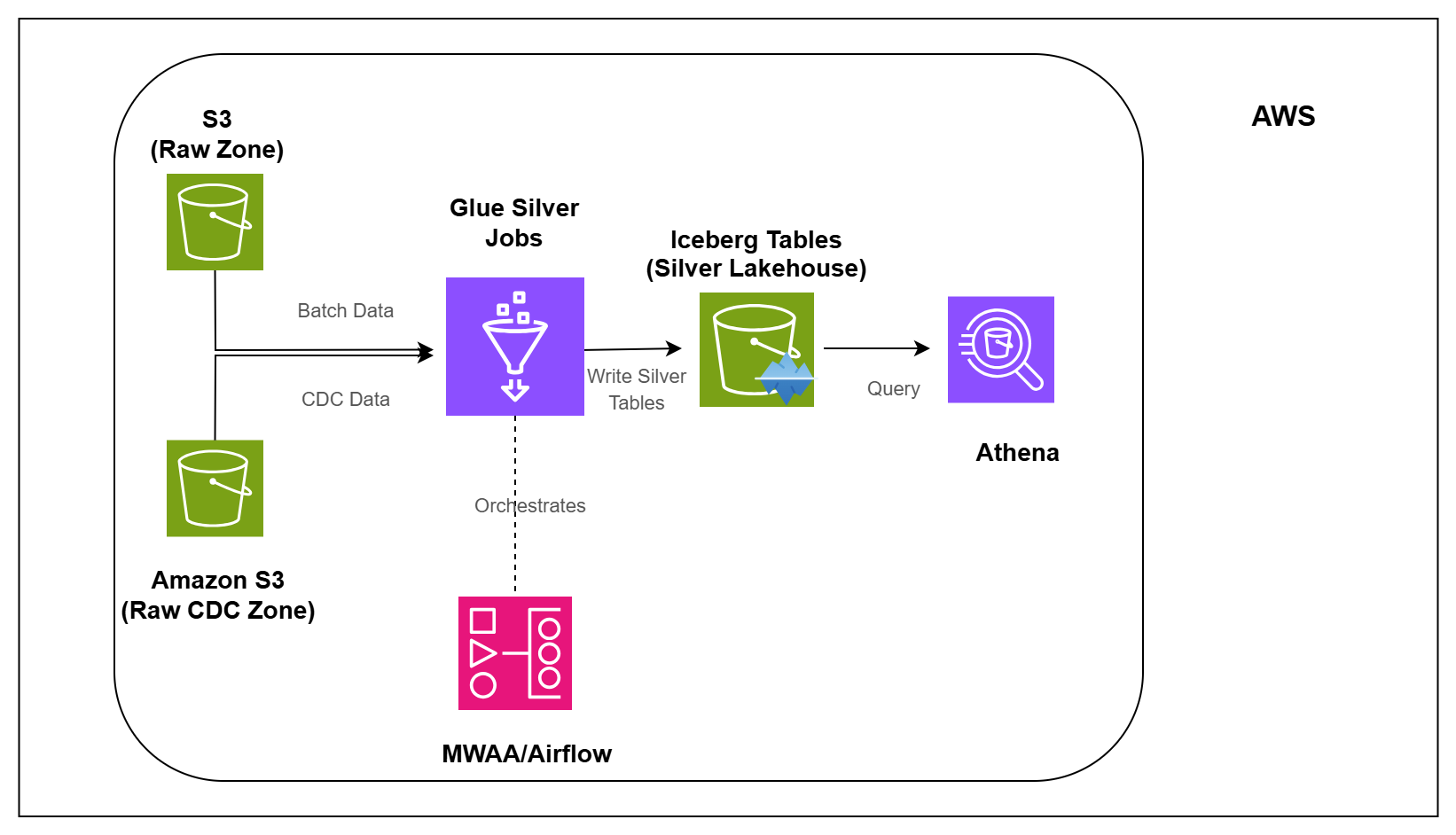
In the first two pipelines, healthcare data was loaded into Amazon S3 using batch and CDC ingestion patterns.
But raw data is usually not ready for direct analytics. It may come from different sources, arrive at different times, contain duplicates, or include both batch and CDC records for the same business entity.
In this pipeline, you will build the next layer of the data platform.
You will take raw healthcare data from Amazon S3, process it using AWS Glue, and create clean Silver tables using Apache Iceberg. These Silver tables act as trusted lakehouse tables that can be used by downstream Gold, analytics, and reporting pipelines.